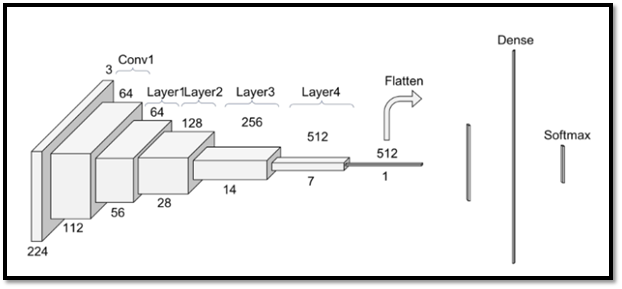
ALEXNET:
Description:
AlexNet is one of the most popular neural network architectures to date. It was proposed by Alex Krizhevsky for the ImageNet Large Scale Visual Recognition Challenge (ILSVRV), and is based on convolutional neural networks. ILSVRV evaluates algorithms for Object Detection and Image Classification. In 2012, Alex Krizhevsky et al. published ImageNet Classification with Deep Convolutional Neural Networks. This is when AlexNet was first heard of.
Configuration:
The data-set contains Train and Test folder. Train folder has 43 different folders named from 0 to 42. Each folder contains images from the respective class. There are also Train.csv and Test.csv files which contains information about the train and test images. All the images are distributed in 43 different classes.
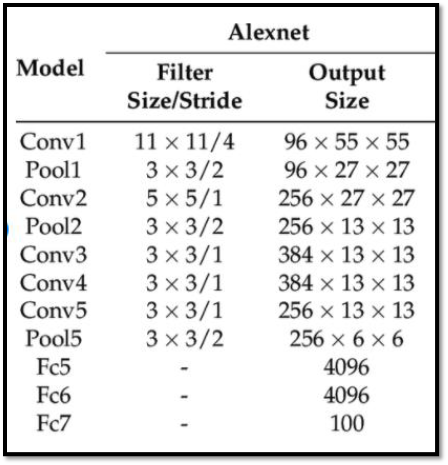
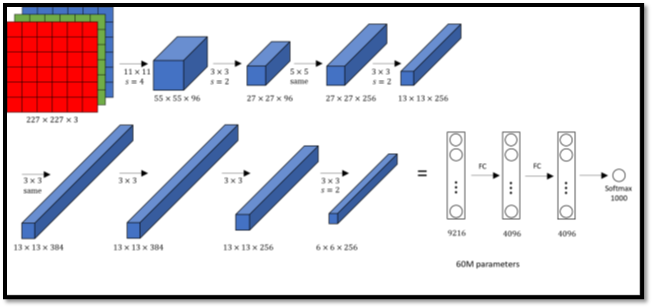
Architecture:
The architecture is comprised of eight layers in total, out of which the first 5 are convolutional layers and the last 3 are fully-connected. The first two convolutional layers are connected to overlapping max-pooling layers to extract a maximum number of features. The third, fourth, and fifth convolutional layers are directly connected to the fully connected layers. All the outputs of the convolutional and fully connected layers are connected to ReLu non-linear activation function. The final output layer is connected o a softmax activation layer, which produces a distribution of 1000 class labels.
VGG-19:
Description:
VGG-19 is a trained Convolutional Neural Network, from Visual Geometry Group, Department of Engineering Science, University of Oxford. The number 19 stands for the number of layers with trainable weights. 16 Convolutional layers and 3 Fully Connected layers.
Configuration:
The screenshot is from the original research paper. The different columns A, A-LRN to E shows the different architectures tried by the VGG team. The column E refers to VGG-19 architecture. The VGG-19 was trained on the ImageNet challenge (ILSVRC) 1000-class classification task. The network takes a (224, 224, 3) RBG image as the input.
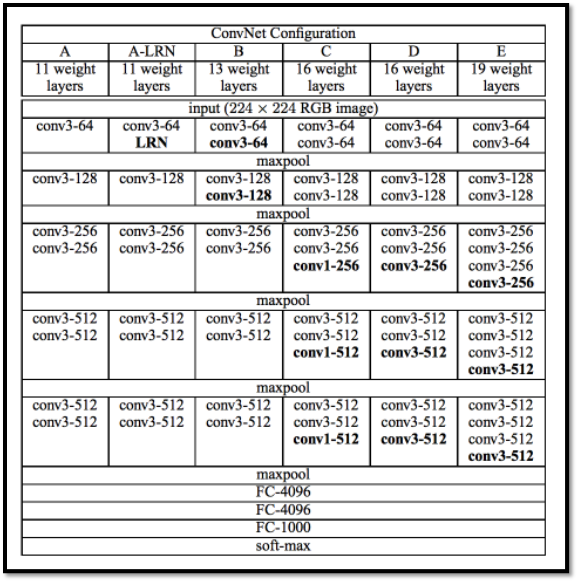
Architecture:
Below diagram shows how layers are represented. conv(size of the filter)-(number of such filters). Thus, conv3-64 means 64 (3, 3) square filters. Note that all the conv layers in VGG-19 use (3, 3) filters and that the number of filters increases in powers of two (64, 128, 256, 512). In all the Conv layers, stride length used in 1 (pixel) with a padding of 1 (pixel) on each side. There are 5 sets of conv layers, 2 of them have 64 filters, next set has 2 conv layers with 128 filters, next set has 4 conv layers with 256 filters, and next 2 sets have 4 conv layers each, with 512 filters. There are max pooling layers in between each set of conv layers. max pooling layers have 2x2 filters with tride of 2 (pixels). The output of last pooling layer is flattened an fed to a fully connected layer with 4096 neurons. The output goes to another fully connected layer with 4096 neurons, whose output is fed into another fully connected layer with 1000 neurons. All these layers are ReLU activated. Finally, there is a softmax layer which uses cross entropy loss. The layers with trainable weights are only the convolution layers and the Fully Connected layers. maxpool layer is used to reduce the size of the input image where softmax is used to make the final decision.
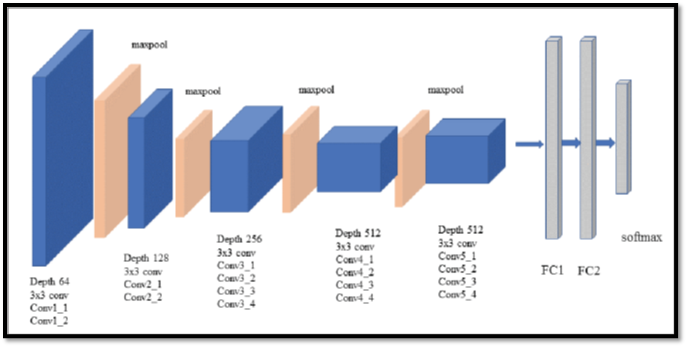
RESNET50:
Description:
one of the bottlenecks of VGG is that they couldn’t go as deep as wanted, because they started to lose generalization capability. ResNets solve’s this known as vanishing gradient. This is because when the network is too deep, the gradients from where the loss function is calculated easily shrink to zero after several applications of the chain rule. This result on the weights never updating its values and therefore, no learning is being performed. With ResNets, the gradients can flow directly through the skip connections ackwards from later layers to initial filters.
Configuration:
ResNet consists of one convolution and pooling step followed by 4 layers of similar behavior. Each of the layers follow the same pattern. They perform 3x3 convolution with a fixed feature map dimension (F) [64, 128, 256, 512] respectively, bypassing the input every 2 convolutions. Furthermore, the width (W) and height (H) dimensions remain constant during the entire layer.
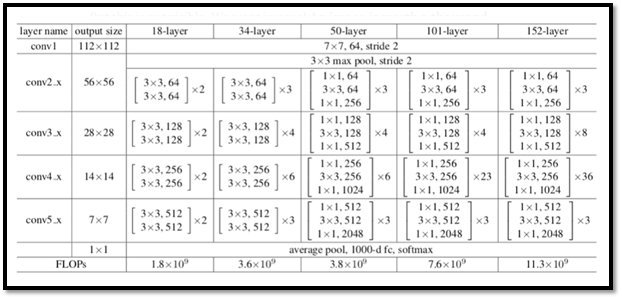
Architecture:
Each ResNet block is 3 layer deep and a convoultion with a kernel size of 7 * 7 and 64 different kernels all with a stride of size 2 giving us 1 layer followed by max pooling with a stride size of 2. In the next convolution there is a 1 * 1,64 kernel following this a 3 * 3,64 kernel and at last a 1 * 1,256 kernel, these three layers are repeated in total 3 time so giving us 9 layers in this step. In next we find kernels of 1 * 1, 3 * 3,128 and at last of 1 * 1,512 this step was repeated 4 time so giving us 12 layers in this step. After that there is a kernal of 1 * 1,256 and two more kernels with 3 * 3,256 and 1 * 1,1024 and this is repeated 6 time giving us a total of 18 layers.And then again a 1 * 1,512 kernel with two more of 3 * 3,512 and 1 * 1,2048 and this was repeated 3 times giving us a total of 9 layers. after that we do a average pool and end it with a fully connected layer containing 1000 nodes and at the end a softmax function so this gives us 1 layer. We don't actually count the activation functions and the max/ average pooling layers. so totaling this it gives us a 1 + 9 + 12 + 18 + 9 + 1 = 50 layers Deep Convolutional network.